

🧩 TL;DR
In this post, I share my early experience contributing to the LLMClient project under the Scala Center as a GSoC 2025 contributor. I walk through my onboarding journey, repo exploration, technical roadblocks, and initial contributions. This work lays the groundwork for a fully modular RAG system in Scala, and I’m excited to share what’s ahead.
🚀 Introduction: A Summer of Code and Curiosity
Hi, I’m Gopi Trinadh Maddikunta — a graduate student in Engineering Data Science at the University of Houston, currently contributing to Google Summer of Code 2025 with the Scala Center.
My GSoC project is focused on enabling embedding support in LLMClient, a library designed for working with large language models in Scala. Embeddings are the bedrock of intelligent retrieval systems like semantic search, document Q&A, and RAG (Retrieval-Augmented Generation).
This post covers my first few weeks: understanding the codebase, breaking things (and fixing them), and setting the stage for meaningful contributions.
🧠 The Mission: Real-World Embeddings in Scala
The core problem is simple: LLMs don’t remember what they haven’t seen. Embeddings give them a way to retrieve relevant context from external documents. My project focuses on:
Supporting OpenAI and VoyageAI embedding providers
Handling real-world input formats:
.txt,.pdf,.docx,.htmlEnabling configuration-driven pipelines
Setting up for integration with vector databases like FAISS.
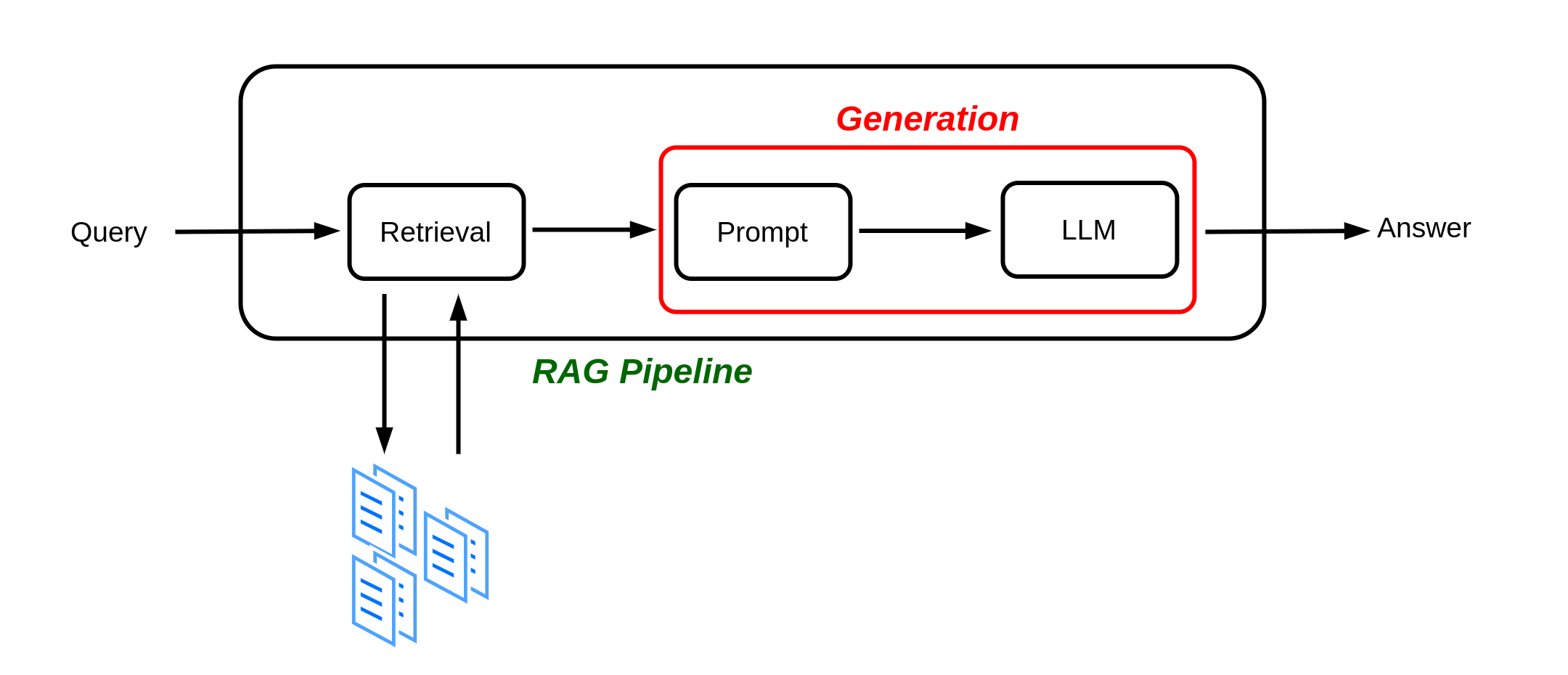
🌍 A Bigger Vision: Building a RAG System
Although my GSoC focus is on embedding support, the long-term plan is to develop a modular Retrieval-Augmented Generation (RAG) system using LLMClient. Here’s the vision:
Document Extraction → Parse PDFs, DOCX, Web
Embedding Generation → Use provider APIs to vectorize content
Retrieval Engine → Index and search using FAISS
Augmented Prompting → Feed top-k results into an LLM
Answer Generation → Stream final responses
Every part of the pipeline will be configurable, extensible, and reusable across backends.
🧭 Exploring the LLM4S Codebase
When I first opened the llm4s repo, I was overwhelmed. Scala wasn’t my daily driver, and the repo had layers. So I broke things down:
📦
llmconnect/– Core embedding logic (providers, client)🧪
samples/– Run-ready code examples🔐
config/–.envloading, model keys📄
model/– Request/Response case classes
To get up to speed, I took the Rock the JVM: Scala at Light Speed course. That gave me just enough to stop being afraid of Either, case class, and for comprehension.
🪓 Git, SBT, and Growing Pains
Before writing code, I had to get the project working. Sounds easy. It wasn’t:
❌ SBT version mismatches (
Scala 2.13vs3.7)❌ Environment variables not detected
❌
sample.pdfnot found → hours lost to a file path❌ Git merge issues from syncing upstream/main
But I logged everything I broke and fixed. That doc now lives next to me every day.
✅ First Wins: From Config to Vector
The best moment? Watching my config-driven code hit the OpenAI endpoint and return a valid embedding vector.
In short:
✅ Loaded
.envconfig with API key✅ Created a working
EmbeddingProviderscaffold✅ Printed JSON output from OpenAI successfully
Now I can toggle between providers, pass sample text, and extract embeddings from live APIs.

🔧 What’s Next
Here’s a snapshot of what’s coming in the next phases:
| Milestone | Status |
|---|---|
| PR 1: OpenAI & VoyageAI Embedding Providers | ✅ Done |
| PR 2: Universal Extractor (Text, PDF, DOCX, HTML) | 🔧 In Progress |
| PR 3: FAISS Integration + Vector Search | 🧩 Coming Up |
| CLI Tool, Chunking, Metadata | 🚧 Scheduled |
🙏 A Quick Shout-Out
Big thanks to my mentors Rory Graves, Kannupriya Kalra and Dmitry Mamonov for their feedback, support, and encouragement. Every review is a learning moment.
🔗 Useful Links
📣 Let’s Connect
If you’re exploring RAG systems, embeddings, or working in Scala — I’d love to hear from you. Blog 2 will dive deep into the architecture, design, and learnings from my first two PRs.
Stay tuned — the real building has just begun.