
🌍 Embedding Anything: Real-World Progress in LLM4S (GSoC 2025, Phase 1)
🧩 TL;DR
This blog shares my GSoC 2025 Phase 1 milestone progress with the Scala Center. I implemented OpenAI and VoyageAI embedding support and built a universal document extractor that reads PDFs, DOCX, HTML, and TXT files. This is part of a larger goal: creating a modular, end-to-end RAG (Retrieval-Augmented Generation) system in Scala.
🎯 Introduction: GSoC, LLM4S, and Why This Matters
As a GSoC 2025 contributor under the Scala Center, I’m working on the LLM4S project. My main goal is to bring embedding support to LLMClient, allowing developers to convert any document into vector representations — a key building block for AI applications like:
-
Semantic Search
-
Q&A over custom data
-
Document classification
-
Retrieval-Augmented Generation (RAG)
Why should you care? Because while RAG systems are popular in Python, Scala developers are left behind. With this work, we’re bridging that gap — and making embeddings, document parsing, and provider switching dead simple in a typed, functional Scala ecosystem.
❓ Why This Milestone Matters
💡 Following mentor advice: explain why/how/what clearly.
✅ Why
Embeddings are the foundation of intelligent retrieval. Without them, your LLM is just guessing. But embedding documents takes work: parsing them, sending them to APIs, handling models, configs, and responses. My work makes that accessible in just a few lines.
🛠️ How
By introducing:
-
A generic interface for any embedding provider (OpenAI, VoyageAI… more coming)
-
A universal extractor for real-world file formats (PDF, DOCX, HTML, TXT)
-
A configuration-first design — swap models/providers with no code changes
🔍 What
Two major PRs:
-
PR #92: Embedding support with OpenAI & VoyageAI
-
PR #100: Universal document extractor
Both are tested, extensible, and designed to fit cleanly into the larger LLMClient ecosystem.
🔧 PR #1: Embedding Support via OpenAI & VoyageAI
🧩 Highlights:
-
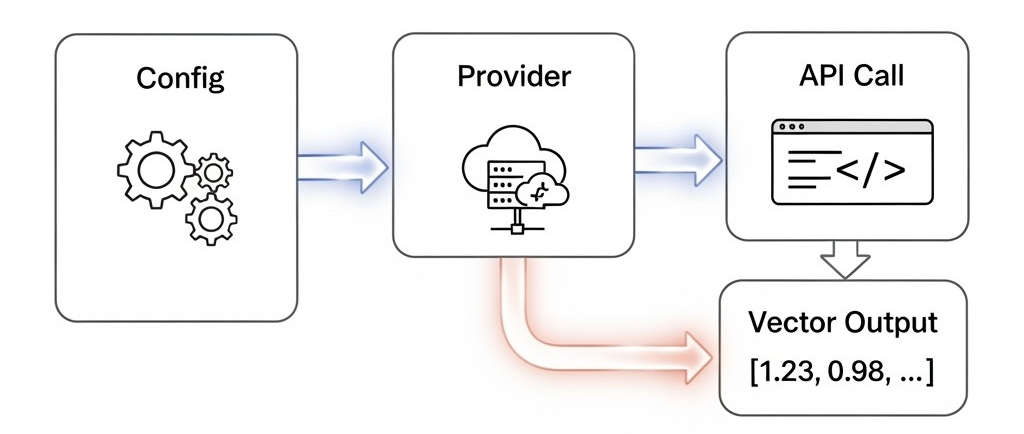
EmbeddingProvidertrait defines a common interface -
OpenAIEmbeddingProviderandVoyageAIEmbeddingProviderfollow it -
Configuration handled through
.envor system props -
Supports model switching (
text-embedding-ada-002,voyage-large-2)
⚙️ Usage:

📂 PR #2: Universal Extractor for Real-World Documents
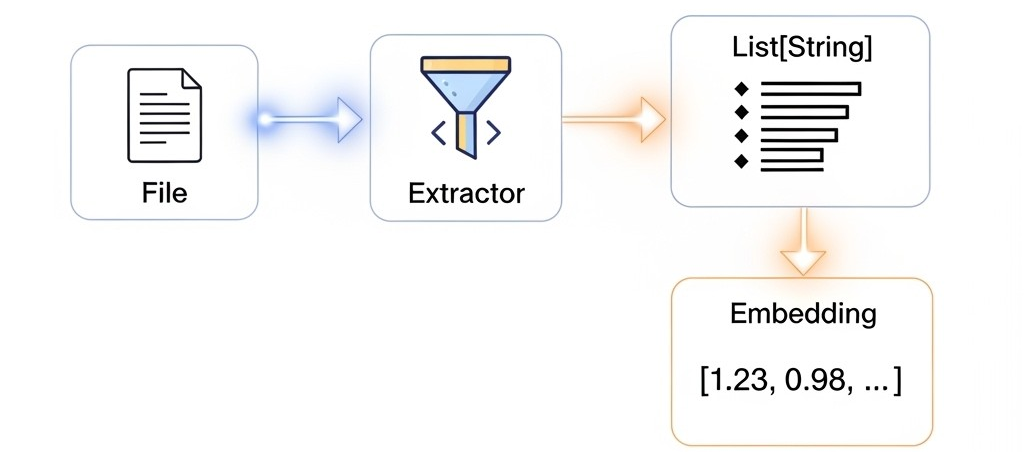
🧠 Supported Formats:
.txt– via standard file reader.pdf– using Apache PDFBox.docx– via Apache POI.html– with JSoup
🧰 Design:
FileExtractortrait defines contractEach format has its own implementation
UniversalExtractordispatches based on file extension
⚙️ Usage:

🧭 RAG Is the Destination
These modules are part of a larger pipeline that looks like this:
| Layer | Status |
|---|---|
| 🧩 Extraction | ✅ Universal Extractor |
| 🔢 Embedding | ✅ OpenAI & Voyage |
| 📦 Storage | 🔜 FAISS Integration |
| 🔍 Retrieval | 🔜 Similarity Scoring |
| 🧠 Generation | 🔜 LLM Response |
🧪 Testing Philosophy
🗒️ Per mentor advice: focus on what matters to the reader — skip trivial unit test details.
Each extractor is tested with real sample files. Providers are tested using mocked or live API responses. No hardcoded paths. Everything is file-safe, clean, and config-driven.
💬 Mentor Feedback (and How It Helped)
Thanks to my mentor Rory Graves, this blog and the implementation behind it followed better structure, clarity, and real-world usefulness. His suggestions led me to:
Frame my work using Why/How/What
Remove redundant detail that didn’t help readers
Focus on meaningful contribution, not just implementation
Think about the reader’s perspective, not just my own
🔗 Useful Links
📣 Wrapping Up
This phase was about making it real. I wrote code that:
Embeds any text via two providers
Parses real documents automatically
Sets the stage for full RAG support in Scala
“Thanks for following along — the code is live, and I’m just getting started.”